2025年9月23日,人工智能领域迎来重大突破——阿里通义实验室正式发布了业界首个原生端到端全模态AI模型Qwen3-Omni,标志着AI技术进入了一个全新的发展阶段。这款革命性产品不仅统一了文本、图像、音频和视频处理能力于单一模型,更在多模态交互、语言支持、实时响应等方面树立了行业新标杆。本文将全面解析Qwen3-Omni的核心技术创新、应用场景及其对AI生态的深远影响。
技术突破:全模态统一架构的革命
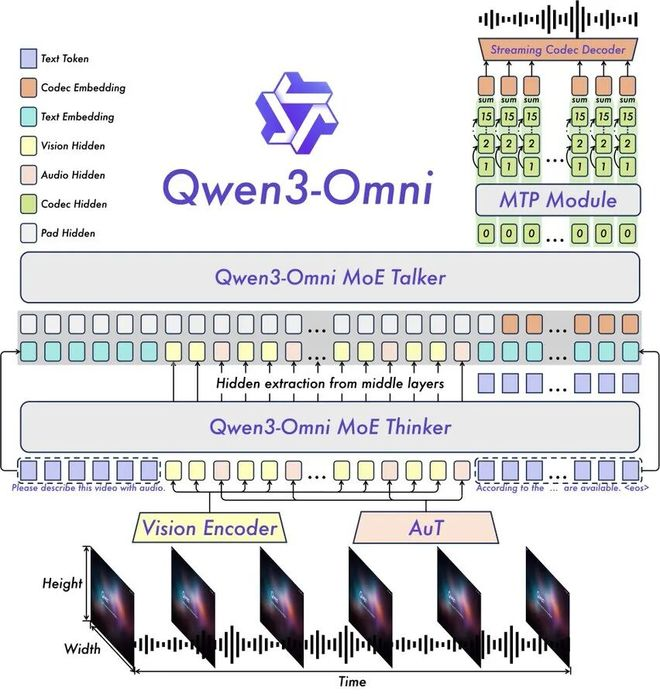
Qwen3-Omni的问世彻底解决了长期以来困扰AI发展的多模态能力权衡难题。传统多模态模型往往需要在不同能力之间做出取舍,导致某些模态性能受限,而Qwen3-Omni通过创新的”思考者-表达者”(Thinker-Speaker)架构设计,实现了真正意义上的全模态统一。
该模型基于MoE(专家混合)技术,结合AuT预训练框架,构建了强大的通用表征能力。特别值得注意的是其多码本设计,将延迟降至惊人的211毫秒,同时支持长达30分钟的音频内容理解。在36项音频及音视频基准测试中,Qwen3-Omni在其中22项达到了业界顶尖水平(SOTA),32项在开源模型中处于领先地位,其自动语音识别(ASR)和语音对话表现已可与Gemini 2.5 Pro相媲美。
模型训练方面,Qwen3-Omni采用了早期以文本为核心的预训练和混合多模态训练策略,使得在实现强大音频与音视频性能的同时,单模态的文本与图像效果保持不降。这种平衡各模态能力的训练方法,为未来多模态AI发展提供了宝贵经验。
全球化语言支持与实时交互
Qwen3-Omni在语言能力方面实现了前所未有的突破,支持119种文本语言处理、19种语音输入语言以及10种语音输出语言。语音输入语言包括英语、中文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语、韩语等主流语言,还特别支持粤语、阿拉伯语、乌尔都语等方言和区域性语言。
语音输出方面,模型支持英语、中文、法语、德语、俄语、意大利语、西班牙语、葡萄牙语、日语和韩语。这种广泛的语言覆盖使Qwen3-Omni真正具备了全球化服务能力,为跨国企业和多语言地区的AI应用提供了强大支持。
实时交互是Qwen3-Omni的另一大亮点。模型支持低延迟流式交互,能够进行自然的轮流对话和即时的文本或语音响应。这种能力使得AI助手能够实现接近人类的对话体验,为客服、教育、娱乐等领域开辟了新的可能性。
开源生态与开发者赋能
秉承阿里”技术普惠”的理念,Qwen团队开源了多个版本的Qwen3-Omni模型,包括Qwen3-Omni-30B-A3B-Instruct、Qwen3-Omni-30B-A3B-Thinking和Qwen3-Omni-30B-A3B-Captioner等。这些开源模型覆盖了从指令遵循到创意任务等多样化的应用场景,为全球开发者提供了强大的工具。
特别值得一提的是开源的Captioner(字幕生成)模型,这是一个通用型、细节丰富、低幻觉率的音频描述模型,填补了开源社区在该领域的空白。该模型能够自动为复杂语音、环境声、音乐、影视声效等生成精准、全面的描述,识别说话人情绪、音乐元素(如风格、乐器)、敏感信息等,适用于音频内容分析、安全审核、意图识别、音频剪辑等多个领域。
开源策略不仅加速了技术进步,也降低了企业采用AI的门槛。开发者可以通过Hugging Face、ModelScope等平台获取这些模型,快速构建自己的多模态应用。
Qwen-Image-Edit-2509:图像编辑新标杆
与Qwen3-Omni同期发布的还有Qwen-Image-Edit-2509,这是Qwen-Image的升级版本,在对标谷歌Nano Banana图像编辑工具的同时,实现了一系列突破性功能。
多图编辑功能是本次升级的核心亮点。用户可以将”人物+产品”或”人物+场景”等多张图片拖入编辑器,系统能够毫无拼接感地实现自然融合。这种能力在1到3张输入图像时表现最佳,为设计师和内容创作者提供了前所未有的便利。
在单图编辑方面,Qwen-Image-Edit-2509实现了三大突破:人脸保真、产品保真和文字编辑。人脸保真技术确保无论变换姿势、滤镜还是风格,人物的面部特征始终保持一致;产品保真功能在广告、海报等应用中,能维持产品的核心特征,确保品牌识别度;文字编辑则支持对图像中的文字进行全面修改,包括内容、字体、颜色甚至材质纹理。
模型还内置了强大的ControlNet功能,用户可以即插即用地实现对图像生成的精准控制,包括深度、边缘、关键点等参数调节。这些功能使Qwen-Image-Edit-2509成为专业设计工作的有力助手,有望重塑图像编辑工作流程。
应用场景与行业影响
Qwen3-Omni的全模态能力为各行业带来了革命性的应用可能。在教育领域,它可以构建真正智能的多语言教学助手,实时解析教材中的文本、图像和视频内容,提供个性化辅导。在医疗行业,模型能够同时处理医学影像、病历文本和医患对话音频,辅助诊断和治疗方案制定。
客服行业将因Qwen3-Omni的实时多语言交互能力而发生变革。企业可以部署支持语音、文字和视频输入的智能客服系统,无缝服务全球客户。媒体和内容创作领域,模型强大的多模态理解和生成能力将极大提升内容生产效率,从自动字幕生成到多语言视频配音,再到智能剪辑,都能实现高度自动化。
Qwen-Image-Edit-2509则在设计、广告和电子商务领域展现出巨大潜力。产品展示图的快速生成和编辑、广告海报的自动化设计、电商产品图的批量处理等任务,都可以通过AI辅助大幅提升效率。特别是对中小企业和个人创作者而言,这些工具极大地降低了专业级图像处理的成本和技术门槛。
技术细节与创新架构
深入探究Qwen3-Omni的技术架构,可以发现多项创新设计。模型基于MoE的”思考者-表达者”架构,通过分离推理过程和输出生成,实现了效率与质量的平衡。这种设计灵感来源于人类认知过程,其中”思考者”模块负责深度分析和推理,”表达者”模块则专注于生成高质量输出。
在音频处理方面,Qwen3-Omni采用了创新的Token化策略,每一秒钟的音频对应25个Token,不足1秒则按25个Token计算。这种高效的表示方法为长音频理解提供了基础,使模型能够处理长达30分钟的音频内容。
模型还支持通过系统提示词(System Prompts)进行完全自定义,用户可以通过精细控制模型行为,满足个性化需求。这种灵活性与内置工具调用(Tool Calling)功能相结合,使Qwen3-Omni能够轻松与其他应用和服务集成,构建复杂的AI工作流。
性能表现与行业对比
在性能方面,Qwen3-Omni在多领域超越了现有模型。音频和音视频处理方面,其在36项基准测试中22项达到SOTA水平,整体表现直逼GPT-5和Gemini 2.5 Pro。延迟控制在211毫秒,远低于行业平均水平,使实时交互成为可能。
与前一版本Qwen2.5-Omni相比,Qwen3-Omni在模型规模、训练数据和能力范围上都有显著提升。Qwen2.5-Omni-7B虽然已经支持文本、音频、图像和视频的多模态处理,但Qwen3-Omni通过30B参数的更大规模和更先进的架构,实现了质的飞跃。
在图像编辑领域,Qwen-Image-Edit-2509与字节跳动的即梦4.0图像模型相比,在多图像编辑和一致性保持方面展现出明显优势。其内置的ControlNet功能也提供了比同类产品更精细的控制选项。
未来展望与行业影响
Qwen3-Omni的发布不仅是一次产品升级,更是AI技术发展的重要里程碑。它标志着多模态AI从”能用”向”好用”的转变,为通用人工智能(AGI)的发展奠定了基础。随着模型能力的不断提升,AI将越来越深入地融入人类工作和生活的各个方面。
未来,我们可以期待Qwen团队在以下方向的进一步突破:更长的上下文理解能力、更多模态的支持(如3D模型、触觉等)、更精细的控制接口,以及更高效的训练和推理方法。这些进步将不断拓展AI的应用边界,创造新的商业价值和社会效益。
对行业而言,Qwen3-Omni的开源策略将加速全球AI创新,降低技术门槛,促进健康竞争。中国企业在这一轮AI竞赛中展现出的技术实力和开放态度,也将重塑全球AI产业格局。
阿里Qwen3-Omni的发布是2025年AI领域最值得关注的事件之一。这款全模态模型以其创新的架构、卓越的性能和广泛的应用前景,为AI技术的发展树立了新标杆。配合Qwen-Image-Edit-2509的强大图像处理能力,阿里正在构建一个覆盖多领域的AI生态系统。
随着这些技术的逐步落地和持续迭代,我们可以预见一个更加智能、高效和互联的未来。Qwen3-Omni不仅是一项技术成就,更是人类探索智能本质道路上的重要里程碑,其影响将远超当前预期,持续塑造数字时代的全新图景。
发表回复